“数据”这个词,是产品经理永远绕不过的话题,但从我多年面试经验看,很多2-3岁的产品经理对数据的理解仍是模糊无章法的,鉴于本人也有着2年的数据产品经验,特整理成文,给产品新人普及一下基本的数据知识。

1、基本概念
什么是“移动App的数据分析”?为什么要进行“移动App的数据分析”?
简单来说,通过在App中进行埋点采集,或读取App存储在数据库中的业务数据,以一定目的,将数据进行“筛选、清洗、加工、解析”,产出对产品设计、运营计划有帮助的结论的过程,就是“数据分析”的过程。持续的数据分析可监控产品的运营状态、提升推广效果、发现产品问题、优化产品体验。
2、基本术语
这里举几个我常遇到的术语,便于同开发和运营进行沟通。
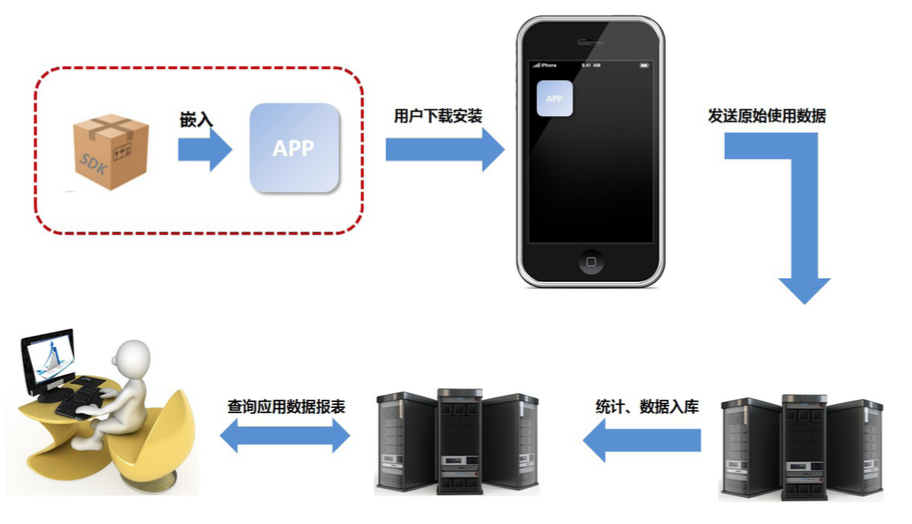
埋点:一般意义上的埋点,是利用如友盟、Talkingdata等第三方公司的SDK,通过在App中嵌入一段SDK代码,设定触发条件,当满足条件时,SDK会记录日志,并将日志发送到第三方服务器进行解析,并可视化地呈现给我们。这一过程就叫埋点。
埋点方式也分“简单埋点”和“自定义埋点”,所谓“简单埋点”就是直接拿到第三方key,写到App代码的配置文件中即可。而“自定义埋点”则对应一种叫“自定义事件”的功能,一般第三方统计工具都支持,我们可通过设置“自定义事件”查看App特定的操作行为数据,如点击按钮次数、打开指定页面次数等。
通常创建“自定义事件”都需要产品经理告知开发App的哪些条件下需要触发“自定义事件”,以及触发时要如何通过不同参数区分不同的点击行为。
如同样是点击按钮事件,可通过设置参数“Action”,来区分Action=Yes和Action=No这两个按钮分别点击的次数。整个埋点流程如下图所示:
维度:维度就是指我们平时看事物的角度,也可理解成分析一个数据能从哪些方面去分析,这些“角度”都是有值且可被枚举的。比如我们注册用户数有10万,那可分析的维度有:用户所在省份、用户性别、用户角色、用户来源等。不同维度来观察数据,可以得出不同结论,能否拓展观察维度,也是评估数据分析能力的一个关键。
度量:度量和维度相辅相成,是指可量化的数值,用于考察不同维度观察的效果,也可理解成“数据指标”。观察度量值可总体查看,如App总用户数,也可配合“维度”分层查看,如不同省份的注册用户数、活跃用户数,不同来源的App启动次数、平均日使用时长等。
渠道:指App的不同安装来源,如通过第三方应用市场安装,通过广告点击安装,通过地推二维码扫码安装,通过官网下载安装等。互联网公司的商务工作一般就是拓展渠道,观察不同渠道带来的数据表现,不断优化渠道质量。
3、基本指标
注:以下所说的指标,均以移动App常见的核心指标为主,不涉及业务相关指标。目的是希望产品经理在谈起某个数据时,能统一认识。
新增用户:安装App后,首次启动App的设备数,需要按“设备号”去重。新增用户主要为了衡量推广效果,以及当前产品在整个生命周期所处阶段。
活跃用户:时间段内,启动过App的设备数,需要按“设备号”去重。活跃用户主要为了衡量运营效果,以及产品使用情况。
启动次数:时间段内,启动App的次数,无需去重。启动次数主要为了衡量推送效果,以及App的内容是否足够吸引人。
留存率:时间段内的新增用户,经过一段时间仍启动App的用户,占原新增用户的比例。“时间段”的划分方式有:按日、按周、按月,对应指标还可细分为“日留存率、周留存率、月留存率”。而“经过一段时间”的划分方式有:次日、7日、14日;次周、+2周;次月、+2月等。一般一款App的次日留存率为30-40%,次月留存率为20%,已经算是不错的成绩了。
使用时长:时间段内,从启动到结束App使用的总时长。所谓“结束App”,通常指杀掉进程,或者将App退到后台超过30秒。一般会按“人均使用时长、次均使用时长、单次使用时长”分析,衡量产品粘性和活跃情况。
使用频率:用户上次启动App的时间,与再次启动的时间差。使用频数分布,可观察到App对用户的粘性,以及运营内容的深度。
4、基本技术
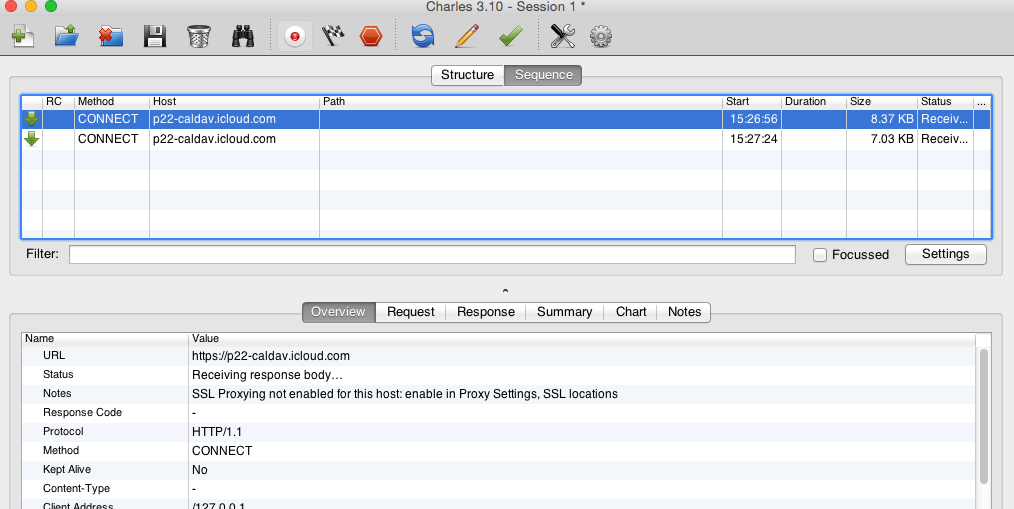
数据采集技术——抓包
所谓“抓包”,一般指观察App上传到服务器上的数据都有哪些。
通过“抓包”观察,一方面可判断自家App是否正确上传了想要统计的数据,另一方面还可抓取到手机上安装的其他App的上传数据,用来分析竞品内容更新情况。
一般在Mac系统上,我习惯用Charles工具,Windows系统可以用Wireshark。当然抓到的数据如果想进行详尽分析,需要一点基本的http协议知识和json格式知识。
数据提取技术——sql语言。sql语言一般用于从数据库中进行数据的增删改查,需要企业运维人员或DBA人员开启权限才可访问,大公司的产品经理基本没机会用到,但如果你是小公司的高级产品经理,且和技术商议仅开启只读权限,还是可以尝试使用的。
以我个人经验,掌握sql只是基本要求,更关键的在于了解数据库表结构和关联关系,以及你提取数据的思路,sql只是工具而已。sql语言本身也和数据库软件相关,推荐学习mysql的sql语法,简单易试。至于语句,只要掌握group by的维度,where的限制条件,还有join语句的表连接逻辑,基本就能应对80%的数据查询需求,剩下的就是熟能生巧了。
数据处理技术——Excel、Python、JS。提取出来的数据,要深入分析,肯定得进行二次加工。按使用的难度高低,需要掌握工具如下:
Excel:大名鼎鼎的office工具,有着极其强大的数据处理能力。常用数据分析功能有透视表和命令行。推荐一个我喜欢的处理命令:
VLOOKUP:这是一个查找函数,给定一个查找目标,它就能从指定的查找区域中返回想要查找到的值。它的基本语法为:
VLOOKUP(查找目标,查找范围,返回值的列数,false)
我们可在一堆数据中,根据指定条件,进行二次筛选,非常方便。当然这个函数的作用还不止如此,有兴趣的同学可以深入研究一下。
此外,包括COUNTIF、IF等判断语句,也是筛选数据非常好用的函数。
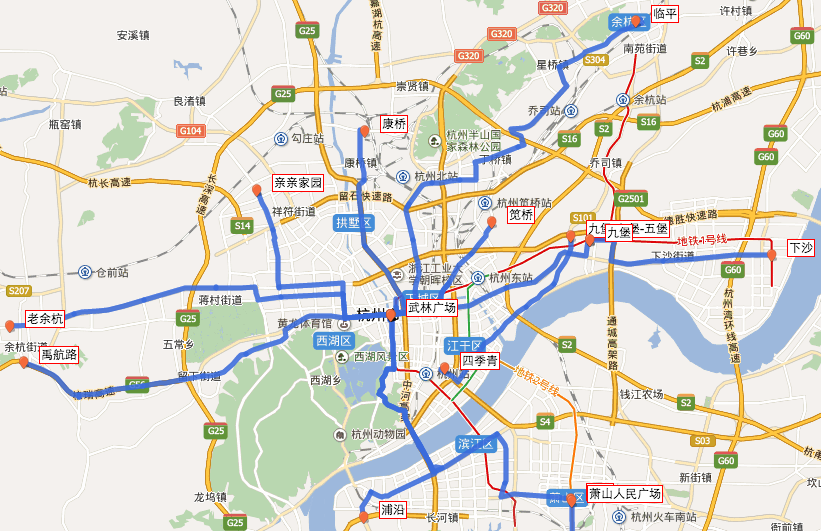
Python、JS:Python、JS其实是一种通用脚本语言,不止适用于数据分析,但由于其安装、使用方便,函数库丰富,特别适合有开发基础的同学尝试。举个例子,mysql提取出来的数据,DBA通常会以Excel格式提供,简单的二次处理可用Excel完成,但涉及根据业务不同,要根据Excel做数据的条件判断计算,以及循环处理,就要借助第三方开发语言了(当然Excel自带的VBA也很强大)。此外,如果希望以更可视化的方式查看数据,还可通过JS技术,调取第三方开发库,如百度地图的API,进行更丰富的呈现。比如之前我在e代驾做的车辆运行轨迹图:
5、基本分析方法
介绍几个常用的数据分析思路:
对比:字面上理解,就是非孤立地看数据,而是多个数据提取进行比较。根据对比方法不同,分为“横向对比”和“纵向对比”。
- 横向对比:指空间维度的对比。相当于一个指标,在不同条件下的对比,但每个条件都属于一个层级。举个例子,App功能的A/B测试数据对比,各个渠道的新增用户对比,都属于横向对比。
- 纵向对比:指时间维度的对比。一般的对比方法有:同比、环比。同比一般指是指本期数据与上年同期数据对比,环比则是本期统计数据与上期比较。观察时间轴上的数据折线图来判断产品运营状态也是一种纵向对比。
拆分:分析这个词,从字面意义上理解,就是“拆分”和“解析”,当某个维度对比后发现问题需要找原因时,就需要进一步“拆分”了。举个例子,如果发现某日的销售额只有昨日的50%,就需要对销售额指标拆分为:成交用户数 x 客单价,而成交用户数 = 访客数 x 转化率。那么我们接下来就可分别针对:访客数、转化率、客单价,观察今日和昨日相比的数据变化,找出原因。
降维:当维度太多时,我们不可能全部分析,这时就要筛选出有代表性的关键维度,去除掉那些无关数据,这就是“降维”。比如“成交用户数 = 访客数 x 转化率”,当同时存在这三个指标时,其实我们只要三选二就能得出结论了。
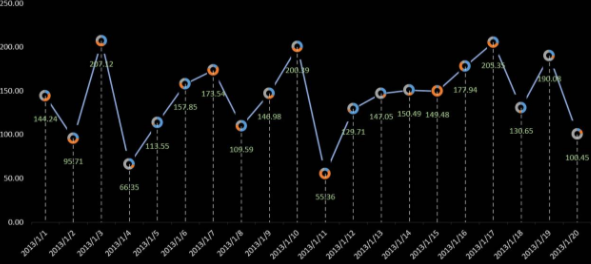
增维:增维和降维是相对的,如果当前观察的维度无法解释当前问题,就需要对数据进行运算,多增加一个指标。在可视化分析领域,也可将不同类型的图表嵌套使用,能达到增加信息展现维度,扩展分析广度的目的,如下图所示:(将环形图和折线图进行增维嵌套)。
分组:也可叫聚类,合适的分组能更好地理解业务和场景。例如用户画像过程,就是一个按不同维度对数据分组的过程。通过用户画像,可以很清晰地知道产品的用户地区、用户兴趣、用户年龄、用户性别等属性占比,产品经理可通过画像进一步了解用户需求。
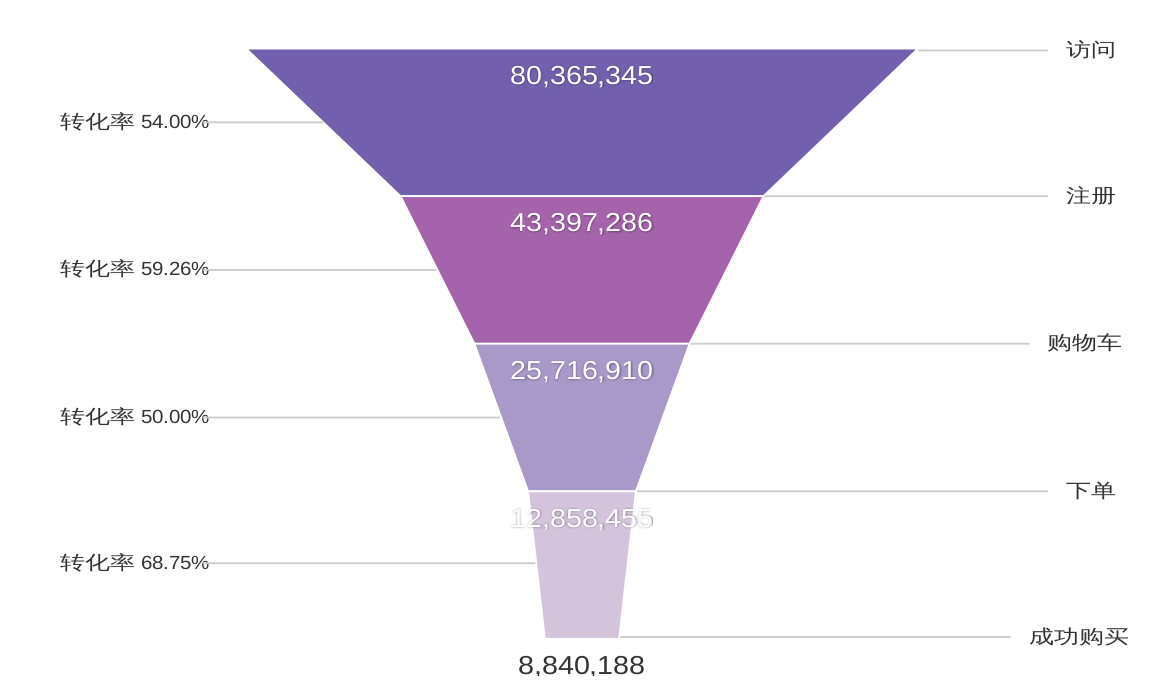
漏斗分析:主要用于分析产品使用的关键路径,通过设定一系列操作步骤,统计每一步中的操作用户数,并将用户数以柱状图纵向排列,就可形成用户流失漏斗,我们可分析漏斗每个环节的流失率,并观察改进环节交互体验后,流失用户的变化情况,以此来验证改动效果。
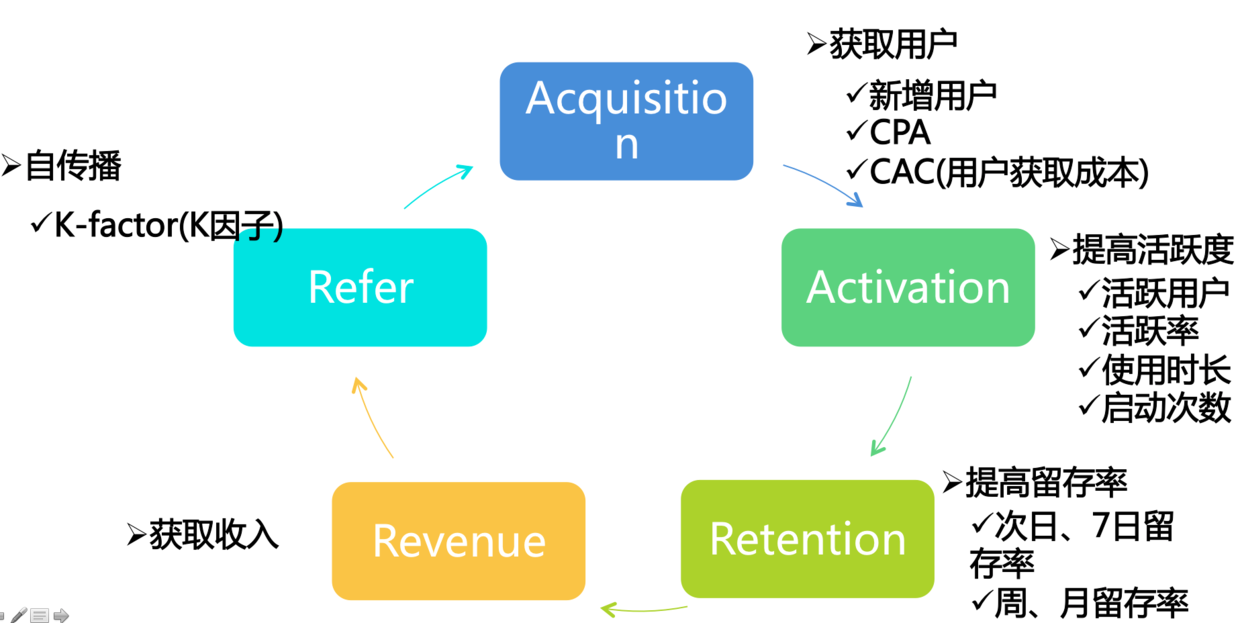
AARRR模型:该模型一般用于游戏数据分析,是Acquisition、Activation、Retention、Revenue、Refer,这五个单词的缩写,分别对应一款移动应用生命周期中的5个重要环节。AARRR本身是一个循环,使用者需观察每个环节的数据情况,以此来分析产品是否在执行一个正循环过程。这其中的任一环节除了问题,都会导致产品数据的异常。
6、总结
以上内容,从“基本概念、基本术语、基本指标、基本技术、基本分析方法”这几个方面,讲解了产品经理应了解的基本数据知识,其实每个方面都可再深入讲解,但由于篇幅有限,只能择期再开新话题,有兴趣的同学可私信或微信沟通~加微信请备注来源哦~